



MySQL的并行复制与组提交
并行复制与组提交是MySQL非常重要的知识点,也是面试中常遇到的问题,现在对其进行一些总结。本文从MySQL主从复制的演化、配置及其背后的原理入手,解释其一些原理和生产中的应用。
1. 主从复制
1.1 mysql主从复制的原理
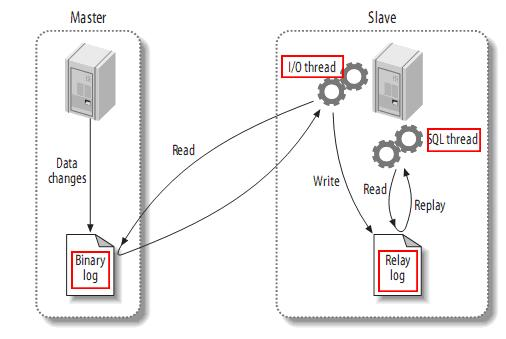
MySQL的主从架构依赖于MySQL Binlog功能,Master节点上产生Binlog并且写入到文件中。
Master节点上启动一个DUMP线程:当Slave节点I/O线程连接Master时,Master创建这个线程,DUMP线程负责从Master的binlog文件读取记录,然后发送给Slave。每个连接到Master的Slave都有一个DUMP线程。
Slave节点上启动两个线程:IO线程和SQL线程,IO线程从MySQL上拉取Binlog日志并写入到本地的RelayLog日志;SQL线程不断从RelayLog日志中读取日志并解析执行,这样就可以保证所有在主服务器上执行过的SQL语句都在从服务器上一模一样的执行过一遍。
- 在复制过程中涉及到的线程
- 从库会开启一个I0 thread(线程),负责连接主库,请求binlog, 接收binlog并写入relay-log。
- 从库会开启一个SQL thread(线程),负责执行relay-log中的事件。
- 主库会开启一个dump thrad(线程),负责响应从I0 thread的请求。
主从复制有三种格式:
-
基于语句的复制:
binlog_format=statementmaster写入执行的SQL语句到binlog中,从库读取这些SQL语句并执行,这种基于SQL语句的复制方式是MySQL最早支持的复制方式。
-
基于行的复制:
binlog_format=rowMySQL5.7.7版本之后,把binlog_format的默认值修改为了row,master将修改表的event写入binlog中,并且master将该binlog发送给slave,slave重放binlog中的event
-
混合模式的复制:
binlog_format=mixed可以将master的binlog_format配置成同时使用基于statement和row两者的组合格式,它记录日志取决于修改的类型,选择合适的格式来记录该修改。默认情况下使用statement格式记录日志,特定情况下转换成基于row格式记录。
2. MySQL主从复制的演进
2.1 MySQL5.1-5.5
2008年11月,MySQL 5.1发布,它提供了分区、事件管理,以及基于行的复制和基于磁盘的NDB集群系统,同时修复了大量的Bug。mysql5.1版本对于复制的新特性就是引入了基于行的复制,当服务器使用混合模式复制时,基于语句的复制是默认的,在运行时会根据具体情况动态的改变binlog格式。当使用混合模式复制时,如下几种情况会从基于语句的binlog切换到基于行:
- 当函数中包含 UUID() 时。
- 2个及以上包含 AUTO_INCREMENT 字段的表被更新时。
- 行任何 INSERT DELAYED 语句时。
- 用 UDF 时。
- 视图中必须要求使用RBR 时,例如创建视图是使用了 UUID() 函数。
2.2 MySQL5.6 schema 级别的并行复制
MySQL5.6版本中引入了一个比较简单的并行复制方案,如果MySQL5.6中开启的并行回放的功能,就会启动多个WorkThread,而原来负责回放的SQLThread会转变成Coordinator角色,负责判断事务能否并行执行并分发给WorkThread。
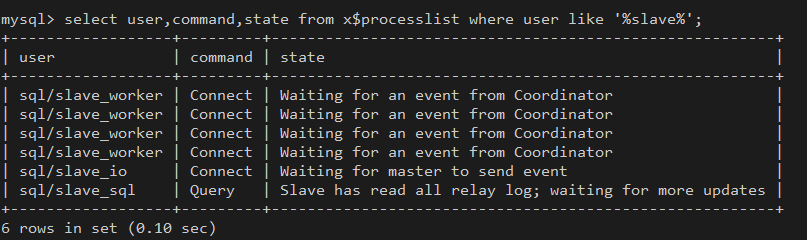
Coordinator线程主要负责:
-
判断relay log中的事务可以并行执行,并协调worker线程执行binlog中的事务。
-
判断不可并行执行,如DDL操作、事务存在跨schema的操作,则等待其他worker线程执行完后,再执行当前无法并行执行的事务。
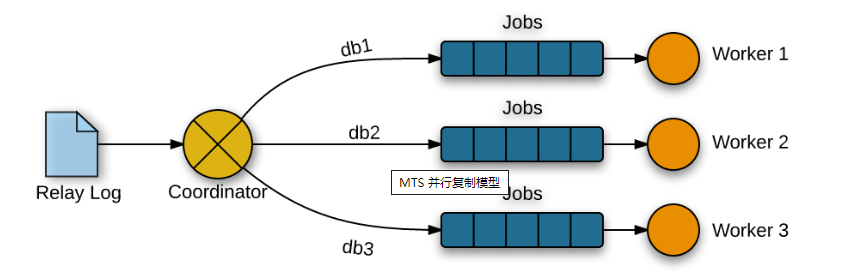
在MySQL5.6版本中的并行复制是基于schema级别的,同时引入了slave_parallel_workers参数来控制并行复制的线程数,默认为0. 这种并行回放是schema级别的,如果实例上有多个schema将会因此受益,如果实例上只有一个schema,那么事务无法并行回放,而且多了分发的过程还增加了耗时。也就是说一个事务内如果涉及到多个schema才能很好地发挥作用。
2.3 MySQL5.6 基于 Group Commit 的并行复制(database)
在mysql5.6 中引入了基于组提交的并行复制。在引入组提交之前,binlog和innodb的redo log是有内部XA机制的(也叫2PC,两阶段提交),保证数据顺序一致性和crush safe。
5.6 中引入Group Commit技术,是为了解决事务提交的时候需要fsync导致并发性不够而引入的。简单来说,就是由于事务提交时必须将Binlog写入到磁盘上而调用fsync,这是一个代价比较高的操作,事务并发提交的情况下,每个事务各自获取日志锁并进行fsync会导致事务实际上以串行的方式写入Binlog文件,这样就大大降低了事务提交的并发程度。
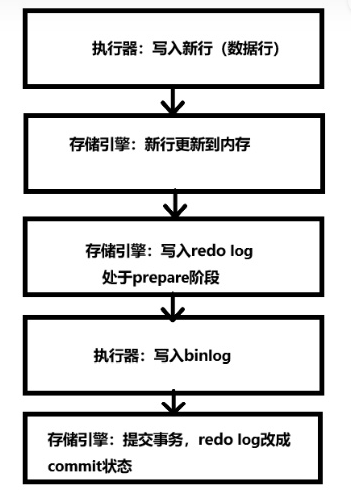
在引入组提交后,二进制日志提交过程分成了三个阶段-- Flush、Sync、Commit,每个阶段都维护一个队列,并且由该队列中第一个线程负责执行该步骤,这样实际上就达到了一次可以将一批事务的Binlog fsync到磁盘的目的,这样的一批同时提交的事务称为同一个Group的事务。
InnoDB Prepare---->Flush Stage---->Sync Stage---->Commit Stage
官方的 Group Commit 分为三个阶段,每个阶段有一个线程操作,三个阶段可以并发执行。
- flush stage:binlog 从 cache 写入文件,实际上是从binlog buffer写到os cache,通知dump线程dump binlog。
- sync stage: 对 binlog 做 fsync,将一组binlog落盘。
- commit stage:innodb引擎层 commit
#230711 23:00:14 server id 118 end_log_pos 322 CRC32 0x921334c7 GTID last_committed=0 sequence_number=1 rbr_only=yes original_committed_timestamp=1689087614942631 immediate_commit_timestamp=1689087618209352 transaction_length=3602
#230711 23:00:14 server id 118 end_log_pos 3924 CRC32 0x3c3b1a8e GTID last_committed=1 sequence_number=2 rbr_only=yes original_committed_timestamp=1689087614976623 immediate_commit_timestamp=1689087618221113 transaction_length=563
#230711 23:00:14 server id 118 end_log_pos 4488 CRC32 0xc1ea4f7f GTID last_committed=2 sequence_number=3 rbr_only=yes original_committed_timestamp=1689087614965418 immediate_commit_timestamp=1689087618329046 transaction_length=147115
#230711 23:00:15 server id 118 end_log_pos 151602 CRC32 0x424c7eb8 GTID last_committed=3 sequence_number=4 rbr_only=yes original_committed_timestamp=1689087615025421 immediate_commit_timestamp=1689087618346393 transaction_length=566
#230711 23:00:15 server id 118 end_log_pos 152168 CRC32 0x74e0c6ae GTID last_committed=3 sequence_number=5 rbr_only=yes original_committed_timestamp=1689087615027950 immediate_commit_timestamp=1689087618346533 transaction_length=566
#230711 23:00:15 server id 118 end_log_pos 152734 CRC32 0xf9486f36 GTID last_committed=3 sequence_number=6 rbr_only=yes original_committed_timestamp=1689087615086448 immediate_commit_timestamp=1689087618347124 transaction_length=2049
#230711 23:00:15 server id 118 end_log_pos 154783 CRC32 0xba83c361 GTID last_committed=3 sequence_number=7 rbr_only=yes original_committed_timestamp=1689087615026638 immediate_commit_timestamp=1689087618347560 transaction_length=566
#230711 23:00:14 server id 118 end_log_pos 155350 CRC32 0x4f8a6f2a GTID last_committed=7 sequence_number=8 rbr_only=yes original_committed_timestamp=1689087615106975 immediate_commit_timestamp=1689087618597358 transaction_length=146531
#230711 23:00:15 server id 118 end_log_pos 301880 CRC32 0x81fd4560 GTID last_committed=8 sequence_number=9 rbr_only=yes original_committed_timestamp=1689087615227764 immediate_commit_timestamp=1689087618615664 transaction_length=4600
#230711 23:00:15 server id 118 end_log_pos 306481 CRC32 0xa93f44d6 GTID last_committed=9 sequence_number=10 rbr_only=yes original_committed_timestamp=1689087615247889 immediate_commit_timestamp=1689087618804116 transaction_length=146997
rbr_only=yes说明基于ROW格式.
sequence_number 是自增事务 ID,last_commited 代表上一个提交的事务 ID。
如果两个事务的 last_commited 相同,说明这两个事务是在同一个 Group 内提交的
2.4 MySQL5.7 基于LOGICAL_CLOCK的并行复制
MySQL5.7中引入了变量slave_parallel_type,可选值为DATABASE、LOGICAL_CLOCK,database就是跟MySQL5.6中相同的(schema级别的并行复制);LOGICAL_CLOCK是基于Group Commit的并行复制,相比5.6提升了并行度。
5.7 的并行复制还有一点弊端,如果如果主库并行度低,那么备库回放时也很难并行。last_committed值相等的事务进行并行处理,由于主库并行度低,造成少量事务的last_committed值是一样的,所以从库即使并行度高也无法高并行度执行。
为此,5.7 引入了两个参数:
binlog_group_commit_sync_delay:等待延迟提交的时间(单位:微秒——us),binlog提交后等待一段时间再 fsync。让每个 group 的事务更多,人为提高并行度。binlog_group_commit_sync_no_delay_count:等待提交的最大事务数,如果等待时间没到,而事务数达到了,就立即 fsync。达到期望的并行度后立即提交,尽量缩小等待延迟。如果binlog_group_commit_sync_delay设置为0则该参数不生效。
2.5 MySQL8.0 基于write set级别的并行复制
5.7 为了提高备库回放的速度,需要在主库尽量提高并行度。
8.0 解决了这个问题,即使主库在串行提交的事务,只有互相不冲突,在备库就可以并行回放。
在8.0中引入了变量binlog_transaction_dependency_tracking和binlog_transaction_dependency_history_size。
参数 transaction_write_set_extraction 决定 hash 算法,可选值:OFF、MURMUR32、XXHASH64,默认值 XXHASH64。
binlog_transaction_dependency_tracking有三个可选项:COMMIT_ORDER、writeset、writeset_session。默认为COMMIT_ORDER。
WriteSet是行数据信息的hash值。
WriteSet=hash(index_name | db_name | db_name_length | table_name | table_name_length | value | value_length)
产生的WriteSet对象会插入到WriteSet哈希表,哈希表的大小由参数binlog_transaction_dependency_history_size设置,默认25000。WriteSet哈希表的类型为std::map<uint64,int64>,保存每条记录的WriteSet值和对应的sequence_number。
binlog_transaction_dependency_tracking=COMMIT_ORDER
在COMMIT_ORDER下,使用的是5.7 group commit的方式,即通过last_committed和sequence_number来判断是否可以并行回放,依然受并发度的影响。
binlog_transaction_dependency_tracking=writeset
在writeset模式下,只要是不同事务的不同记录不重叠,都可以进行并行回放,并行的粒度细化为记录级别。通过判断writeset(记录hash值)是否相同,如果相同则为同一记录,不同则为不同记录,可进行并回放。
在写日志时,每当事务提交时,如果hash表中没有相同的WriteSet,则插入hash表中,二进制日志中的last_committed值不变;如果有,则last_committed更新为sequence_number。last_committed和sequence_number代表LOGICAL_CLOCK。
WriteSet的性能比Commit_Order要快5~6倍,效果非常明显。如果是有延迟要追的,WriteSet毫无疑问是胜者。Commit_Order的瓶颈依然是需要主有足够的并发度,实际生产上确很难达到,除非是业务高峰期。
回放时和基于COMMIT_ORDER的并行复制一样,具有相同的last_committed值可以并行回放,同一条记录回放,last_committed值必然不同,必须等待之前的一条记录回放完成后才能执行。所以透过现象看本质基于Write Set的方式只是在以前的方式上对last_committed做了更进一步的处理,来达到最大的并发效果。
binlog_transaction_dependency_tracking=writeset_session
在WriteSet的基础上增加了一个约束,在主库上同一个session执行的事务,在备库中不可并行,保证顺序性。
3. 相关的配置项
# 主库
binlog_group_commit_sync_delay=100
binlog_group_commit_sync_no_delay_count=10
# 从库
#MUlti-thread线程配置
slave_parallel_type=logical_clock
slave_parallel_workers=8
slave_preserve_commit_order=1
master_info_repository=TABLE
relay_log_info_repository=TABLE
relay-log-recovery = ON
log_slave_updates=1
# MySQL8.0基于WriteSet的复制
binlog_transaction_dependency_history_size=25000
binlog_transaction_dependency_tracking=COMMIT_ORDER
4. 出现主从延迟的几种情况
-
网络原因:网络延迟、抖动、丢包、带宽打满等会影响主从同步。
-
从库负载高:从库有业务读流量,或者其他原因等,会导致无法及时处理主库发来的数据,造成延迟。
-
主库负载高:主库负载高,无法很好地发送数据到从库。
-
主库有大事物:
比如大量导入数据,INSERT INTO tb1 SELECT * FROM tb2、LOAD DATA INFILE等
比如UPDATE、DELETE了全表等
通过show slave status\G命名可以观察到
Exec_Master_Log_Pos一直未变,Slave_SQL_Running_State为Reading event from the relay log,分析主库binlog,看主库当前执行的事务也可知晓。 -
并行复制设置参数不合理:主库多线程写,从库并行回放设置的woker线程少。
-
大表DDL
1、DDL未开始,被阻塞,SHOW SLAVE STATUS检查到Slave_SQL_Running_State为waiting for table metadata lock,且Exec_Master_Log_Pos不变。
2、DDL正在执行,SQL Thread单线程应用导致延迟增加。
Slave_SQL_Running_State为altering table,Exec_Master_Log_Pos不变 -
从库性能差:机器配置差,主库大量数据过来,从库回放慢。
5. 主从延迟处理方式
- 网络原因:更换网卡硬件,增加带宽,优化网络架构等
- 从库硬件升配,增加从库数量,切一部分流量到新的节点,降低压力。
- 主库负载高,优化主库,硬件升配,优化SQL。
- 有大事务,进行事务拆分,分批操作。
- 注意版本特性,规避主从复制的一些bug和兼容性影响。
随着 MySQL 版本迭代,备库回放效率越来越高,为了保证主备同步时效性,可以尽量使用新版本 MySQL
同时,为了保证备库回放效率,应该根据业务模型适当设置复制相关参数。
比如 5.7 可以适当调大 binlog_group_commit_sync_delay 以提高主库并行度,同时设置 binlog_group_commit_sync_no_delay_count 在已满足并行度要求时主动提交,尽量减小延迟。
在 8.0 中根据数据库配置高低设置binlog_transaction_dependency_history_size,性能有富余的实例可以适当调大该参数,找到更小的 commit parent,提高备库回放并行度。内存和CPU紧张的实例最好避免在 WriteSet上消耗太多资源。binlog_transaction_dependency_history_size 过大,不光消耗内存,还会降低冲突查询的效率。
评论区