



mysql count(*)的底层实现和其优化
在业务中经常使用count(*)来计算行数,当有人问起其实现方式时,不能很好的解答?,现在写一篇文章记录一下。
1. 不同的存储引擎有不同的实现方式
-
MyISAM
MyISAM 引擎把一个表的总行数存在了磁盘上,因此执行 count(*) 的时候会直接返回这个数,效率很高。
-
InnoDB
执行 count(*) 的时候,需要把数据一行一行地从引擎里面读出来,然后累积计数。
有如下一些问题:
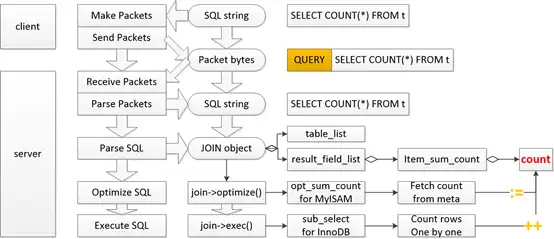
对于innodb来说,count(*)的时候,是把叶子结点全部扫描一遍吗?扫描的是二级索引的叶子结点还是主键索引的叶子结点?
-
执行过程是怎样的?
-
如何计算 count?影响 count 结果的因素有哪些?
-
count 值存在哪里?涉及的数据结构是怎样的?
-
为什么 InnoDB 只能通过扫表来实现 count( * )?
-
全表COUNT( * )作为 table scan 类型操作的一个 case,有什么风险?
-
COUNT(* )操作是否会像“SELECT * ”一样可能读取大字段涉及的溢出页?
2. 不同的count用法
在 select count(?) from t 这样的查询语句里面,count(*)、count(主键 id)、count(字段) 和 count(1) 等不同用法的性能,有哪些差别?
首先要弄清楚 count() 的语义。count() 是一个聚合函数,对于返回的结果集,一行行地判断,如果 count 函数的参数不是 NULL,累计值就加 1,否则不加,最后返回累计值。
有如下两张表:
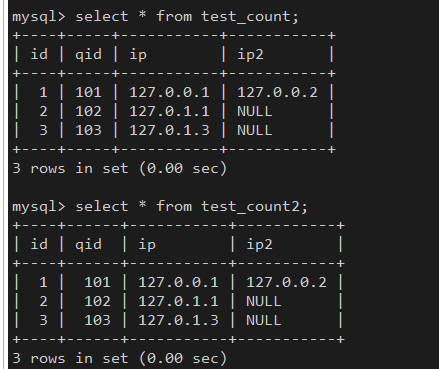
查看各种count的执行结果和执行计划:
count(*)
mysql> select count(*) from test_count2;
+----------+
| count(*) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
mysql> explain select count(*) from test_count2;
+----+-------------+-------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
| 1 | SIMPLE | test_count2 | NULL | index | NULL | idx_ip | 402 | NULL | 3 | 100.00 | Using index |
+----+-------------+-------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
从执行计划上看,是走了二级非空字段索引。
count(1)
mysql> select count(1) from test_count2;
+----------+
| count(1) |
+----------+
| 3 |
+----------+
1 row in set (0.00 sec)
mysql> explain select count(1) from test_count2;
+----+-------------+-------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+-------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
| 1 | SIMPLE | test_count2 | NULL | index | NULL | idx_ip | 402 | NULL | 3 | 100.00 | Using index |
+----+-------------+-------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
count(ip2) – default null
mysql> select count(ip2) from test_count;
+------------+
| count(ip2) |
+------------+
| 1 |
+------------+
1 row in set (0.00 sec)
mysql> explain select count(ip2) from test_count;
+----+-------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
| 1 | SIMPLE | test_count | NULL | index | NULL | idx_ip2 | 403 | NULL | 3 | 100.00 | Using index |
+----+-------------+------------+------------+-------+---------------+---------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
count的字段有null值是不计算在总数内的,会走对应字段的索引。
更准确的说,单列索引不存储null值,复合索引不存储全为null的值。索引不能存储Null,所以对这列采用is null条件时,因为索引上根本没Null值,不能利用到索引,只能全表扫描。
为什么索引列不能存Null值?
将索引列值进行建树,其中必然涉及到诸多的比较操作。Null值的特殊性就在于参与的运算大多取值为null。
这样的话,null值实际上是不能参与进建索引的过程。也就是说,null值不会像其他取值一样出现在索引树的叶子节点上。
count(ip)–not null default ‘’
写入一条ip为空字符串的数据后测试
mysql> insert into test_count(qid) values (104);
Query OK, 1 row affected (0.01 sec)
mysql> select count(ip) from test_count;
+-----------+
| count(ip) |
+-----------+
| 4 |
+-----------+
1 row in set (0.00 sec)
mysql> explain select count(ip) from test_count;
+----+-------------+------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
| 1 | SIMPLE | test_count | NULL | index | NULL | idx_ip | 402 | NULL | 4 | 100.00 | Using index |
+----+-------------+------------+------------+-------+---------------+--------+---------+------+------+----------+-------------+
1 row in set, 1 warning (0.00 sec)
可以看到空字符串被计数了。
总结
-
count(*)与count(1)没什么区别的,也就没有COUN(1)会比COUNT(*)更快这一说了。type都是 index 索引全扫描,优化器会选择一个非空字段上的、key_len总大小比较小(占用空间最小)的字段的二级索引进行统计。 -
查询时,不判断数据内容,只判断数据行数
-
Q: InnoDB-COUNT( * ) 属 table scan 操作,是否会将现有 Buffer Pool 中其它用户线程所需热点页从 LRU-list 中挤占掉,从而其它用户线程还需从磁盘 load 一次,突然加重 IO 消耗,可能对现有请求造成阻塞?
A:MySQL 有这样的优化策略,将扫表操作所 load 的 page 放在 LRU-list 的 oung/old 的交界处 ( LRU 尾部约 3/8 处 )。这样用户线程所需的热点页仍然在 LRU-list-young 区域,而扫表操作不断 load 的页则会不断冲刷 old 区域的页,这部分的页本身就是被认为非热点的页,因此也相对符合逻辑。
-
对于
count(主键id)来说,InnoDB引擎会遍历整张表,把每一行的id值都取出来,返回给server层。server层拿到id后,判断是不可能为空的,就按行累加。对于
count(1)来说,InnoDB引擎遍历整张表,但不取值。server层对于返回的每一行,放一个数字“1”进去,判断是不可能为空的,按行累加。单看这两个用法的差别的话,你能对比出来,count(1)执行得要比count(主键id)快。因为从引擎返回id会涉及到解析数据行,以及拷贝字段值的操作。
对于
count(字段)来说,如果这个“字段”是定义为not null的话,一行行地从记录里面读出这个字段,判断不能为null,按行累加;如果这个“字段”定义允许为null,那么执行的时候,判断到有可能是null,还要把值取出来再判断一下,不是null才累加。
最后count(*)是例外,并不会把全部字段取出来,而是专门做了优化,不取值。count(*)肯定不是null,按行累加。
按照效率排序的话:count(字段)<count(主键id)<count(1)≈count(\*)
参考文档:
MySQL 全表 COUNT(*) 简述 - 知乎 (zhihu.com)
MySQL执行计划的type列和extra列 - 墨天轮 (modb.pro)
评论区