



Redis cluster原理
Redis Cluster 是Redis的集群实现,内置数据自动分片机制,集群内部将所有的key映射到16384个Slot中,集群中的每个Redis Instance负责其中的一部分的Slot的读写。集群客户端连接集群中任一Redis Instance即可发送命令,当Redis Instance收到自己不负责的Slot的请求时,会将负责请求Key所在Slot的Redis Instance地址返回给客户端,客户端收到后自动将原请求重新发往这个地址,对外部透明。一个Key到底属于哪个Slot由crc16(key) % 16384 决定。
关于负载均衡,集群的Redis Instance之间可以迁移数据,以Slot为单位,但不是自动的,需要外部命令触发。
关于集群成员管理,集群的节点(Redis Instance)和节点之间两两定期交换集群内节点信息并且更新,从发送节点的角度看,这些信息包括:集群内有哪些节点,IP和PORT是什么,节点名字是什么,节点的状态(比如OK,PFAIL,FAIL,后面详述)是什么,包括节点角色(master 或者 slave)等。
关于可用性,集群由N组主从Redis Instance组成。主可以没有从,但是没有从 意味着主宕机后主负责的Slot读写服务不可用。一个主可以有多个从,主宕机时,某个从会被提升为主,具体哪个从被提升为主,协议类似于Raft,参见这里。如何检测主宕机?Redis Cluster采用quorum+心跳的机制。从节点的角度看,节点会定期给其他所有的节点发送Ping,cluster-node-timeout(可配置,秒级)时间内没有收到对方的回复,则单方面认为对端节点宕机,将该节点标为PFAIL状态。通过节点之间交换信息收集到quorum个节点都认为这个节点为PFAIL,则将该节点标记为FAIL,并且将其发送给其他所有节点,其他所有节点收到后立即认为该节点宕机。从这里可以看出,主宕机后,至少cluster-node-timeout时间内该主所负责的Slot的读写服务不可用。
Redis cluster主从复制原理
Redis的主从复制功能除了支持一个Master节点对应多个Slave节点的同时进行复制外,还支持Slave节点向其它多个Slave节点进行复制。这样就使得架构师能够灵活组织业务缓存数据的传播,例如使用多个Slave作为数据读取服务的同时,专门使用一个Slave节点为流式分析工具服务。
Redis的主从复制功能分为两种数据同步模式进行:全量数据同步和增量数据同步。
全量同步
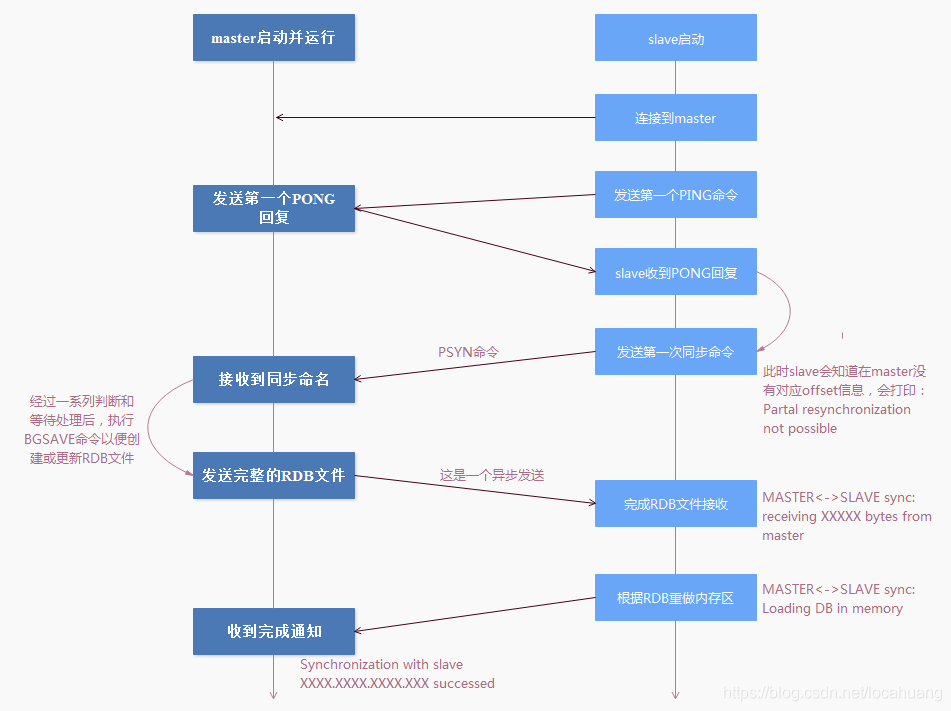
什么时候进行全量同步?
- 当Slave节点给定的replication id和Master的replication id不一致时;
- 或者Slave给定的上一次增量同步的offset的位置在Master的环形内存中(replication backlog)无法定位时。
Master就会对Slave发起全量同步操作。
全量同步的时候,无论是否在Master打开了RDB快照功能,它和Slave节点的每一次全量同步操作过程都会更新/创建Master上的RDB文件。
在Slave连接到Master,并完成第一次全量数据同步后,接下来Master到Slave的数据同步过程一般就是增量同步形式了(也称为部分同步)。增量同步过程不再主要依赖RDB文件,Master会将新产生的数据变化操作存放在replication backlog这个内存缓存区,这个内存区域是一个环形缓冲区,也就是说是一个FIFO的队列。
特点:
- 主节点通过BGSAVE命令fork子进程进行RDB持久化,该过程是非常消耗CPU、内存(页表复制)、硬盘IO。
- 主节点通过网络将RDB文件发送给从节点,对主节点的带宽都会带来很大的消耗。
- 从节点清空数据、载入新RDB文件的过程是阻塞的,无法响应客户端的命令;如果从节点执行bgrewriteaof,也会带来额外的消耗。
增量同步
Redis2.8开始提供部分复制,用于处理网络中断时的数据同步。进行增量同步 — master作为一个普通的client连入slave,将所有写操作转发给slave,没有特殊的同步协议。具体过程如下:
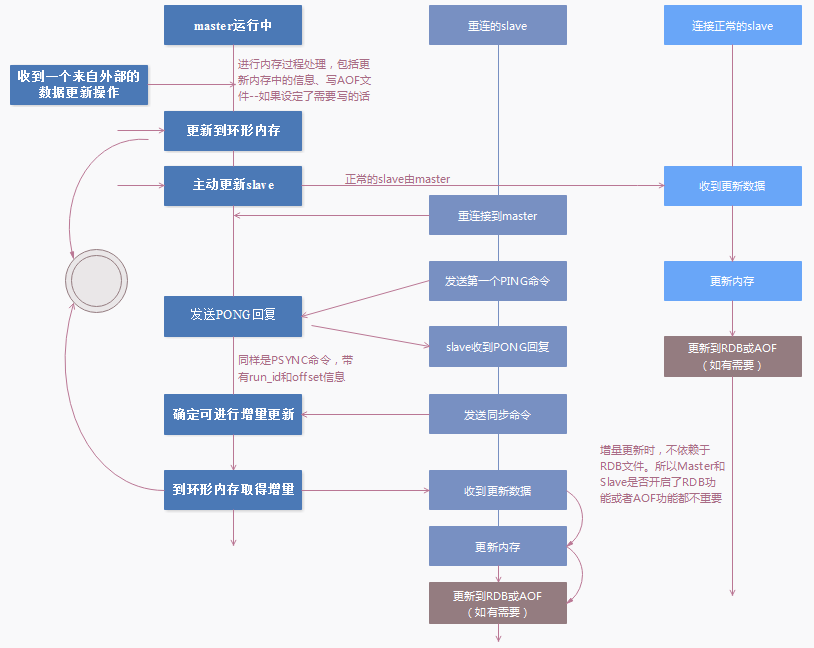
问:为什么在Master上新增的数据除了根据Master节点上RDB或者AOF的设置进行日志文件更新外,还会同
时将数据变化写入一个环形内存结构(replication backlog),并以后者为依据进行Slave节点的增量更新呢?主要原因有以下几个:
- 由于网络的不稳定,网络抖动/延迟都可能造成slave和master暂时断开连接,这种情况远多于新的slave连接到master的情况。如果以上所有情况都使用全量更新,就会大大增加master的负载压力–写RDB文件是有大量I/O过程的,虽然Linux Page Cache特性会减少性能消耗。
- 另外在数据量达到一定规模的情况下,使⽤全量更新进行和Slave的第一次同步是一个不得已的选择–因为要尽快减少Slave节点和Master节点的数据差异。所以只能占用Master节点的资源和网络带宽资源。
- 使用内存记录数据增量操作,可以有效减少Master节点在这方面付出的I/O代价。而做成环形内存的原因,是为了保证在满⾜数据记录需求的情况下尽可能减少内存的占用量。这个环形内存的大小,可以通过repl-backlog-size参数进行设置。
Slave重连后会向Master发送之前接收到的Master replication id信息和上一次完成部分同步的offset的位置信息。如果Master能够确定这个replication id和自己的replication id(有两个)一致且能够在环形内存中找到这个offset的位置,Master就会发送从offset的位置开始向Slave发送增量数据。
问:连接正常的各个Slave节点如何接受新数据呢?
连接正常的Slave节点将会在Master节点将数据写入环形内存后,主动接收到来自Master的数据复制信息。
问:Replication backlog的size设置多大合适呢?
redis为Replication backlog设置的默认大小为1M,这个值可以调整。如果主服务需要执行大量的写命令,又或者主服务之间断线后重连的时间比较长,那么这个大小也许不合适。如果replication backlog的大小设置不恰当,那么PSYNC命令的复制同步模式就不能正常发挥作用,因此,正确估算和设置replication backlog的size非常重要。
计算参考公式:size = reconnect_time_second * write_size_per_second*2
例如如果网络中断的平均时间是60s,而主节点平均每秒产生的写命令(特定协议格式)所占的字节数为100KB,则复制积压缓冲区的平均需求为6MB,保险起见,可以设置为12MB,来保证绝大多数断线情况都可以使用部分复制。
当主服务器进行命令传播的时候,maser不仅将所有的数据更新命令发送到所有slave的replication buffer,还会写入replication backlog。当断开的slave重新连接上master的时候,slave将会发送psync命令(包含复制的偏移量offset),请求partial resync。如果请求的offset不存在,那么执行全量的sync操作,相当于重新建立主从复制。
区分replication buffer 和 replication backlog
1) replication buffer对应于每个slave,通过config set client-output-buffer-limit slave 设置。
2) replication backlog是一个环形缓冲区,整个master进程中只会存在一个,所有的slave公用。backlog的大小通过repl-backlog-size参数设置,默认大小是1M。
其大小可以根据每秒产生的命令 乘以((master执行rdb bgsave的时间)+ (master发送rdb到slave的时间) + (slave load rdb文件的时间) ) ,来估算积压缓冲区的大小,repl-backlog-size值不小于这两者的乘积。
- master执行rdb bgsave产生snapshot的时间
- master发送rdb到slave网络传输时间
- slave load rdb文件把数据恢复到内存的时间
总结
由此可见,Redis的主从同步非常依赖于两个参数的合理配置:
repl-backlog-size
client-output-buffer-limit
评论区